
“Data is the new oil” - someone, probably.
Indeed, we live in the golden age of information. As we produce more and more data every day, the skill of extracting that gold nugget of knowledge amongst the endless noise is becoming increasingly valuable.
Whether you are building the next great ML model, scraping websites, or dealing with data in any other way, at your work or as a fun side-project, you have already dipped your toes in the messy swamp that is the world of ETL (Extract, Transform, Load).
In this post I will introduce you to my good friend AWS Glue - a service (actually, several services) I, despite many sleepless nights and salty tears being shed over it, grew to 💛 love 💛! I will mostly focus on Glue ETL jobs, but other members of the Glue family will also get a mention.
It’s a great tool to have in your arsenal and you don’t need to deal exclusively with #BigData to get the most of the features it brings.
Synopsis
What you’ll learn
Although this post is about AWS Glue, you are not expected to have any familiarity with ETL or Spark. By the end you will have learned about:
- AWS Glue, its different components and flavours
- Why use it, irregardless of the size or shape of your data
You will also write your very own Glue job in the AWS Console.
In any case - let’s get started!
Prerequisites
All you will need is the following:
- AWS Account,
- Basic experience with Python,
- An IDE/text editor, my recent fave is VS Code.
What is ETL anyway?
I briefly broke down the initialism ETL above as “Extract, Transform, Load”. But in more human terms, it’s as simple as:
- Extract - Read some data from its source(s),
- Transform - Change its shape/contents,
- Load - Write the output to some destination.

In other words, it is a complete “job” of a data pipeline. Either a Python script running on your laptop that reads some text file and prints the output, or a massive EMR cluster running daily Spark jobs, processing petabytes of data - ETL comes in all shapes and sizes!
Intro to Glue
AWS Glue is a family of services that make up an all-inclusive, managed and serverless ETL solution. It acts as the “glue” holding together your data that is scattered across the different AWS data stores - S3, DynamoDB, Aurora, RedShift, PostgreSQL - you name it!
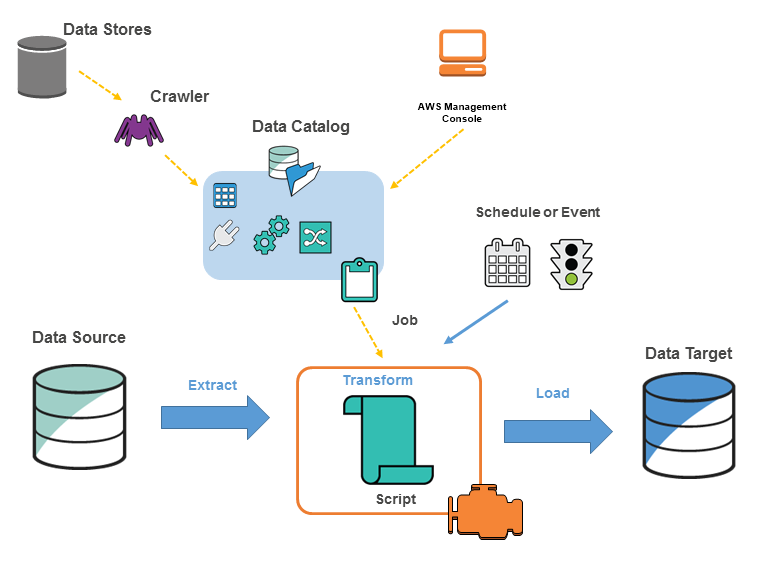 Glue Environment Architecture, source: AWS
Glue Environment Architecture, source: AWS
At the core sits the Glue Data Catalog, which stores metadata for your different data sets as tables* in a database*, allowing them to be easily queried in Athena, processed in an ETL job etc. It abstracts away details such as the location of the data, what service it is stored on etc., allowing you to, for example, join a RedShift table with a DynamoDB table and the output as another table stored on S3, without knowing what in the world a “range key” or “global secondary index” even is.
* Note: These are not tables or databases in the traditional sense. Tables are just a generic metastore (you can define a table as any random blob of metadata, really), while a database is just a namespace to group tables together.
Aiding this “I don’t care about the details” approach to ETL are Glue Crawlers 🕷️ - fully-managed scheduled or on-demand jobs that, given some data source, crawls it to infer its schema (attributes, their types, partitions) and adds it as a table to the catalog, allowing it to be processed easily in Glue ETL Jobs.
But all of this is completely optional! In fact - this time around we will only be working with Glue jobs, accessing our data directly.
Why use it?
Glue has many things going for it. Here are some of them:
- Serverless - just write the job and run it. No need to provision hosts or choose instance types. You are only billed per second that your job is running.
- Preconfigured - comes pre-loaded with most dependencies you might need.
- Scaling - easy to scale and “productionize” scripts you have already - is your data getting bigger? Just change one parameter to scale it up!
- Connectors to many different data sources and sinks
- ML Transforms - use an ML model to clean your data, e.g. find duplicates based text similarity. Glue not only comes with some out of the box, but also provides tooling to train, validate and use your own.
- Relationalization - allows you to flatten and explode complex data for easy querying/dashboarding
- Designed to deal with “dirty” data, with features including lazy schema inference, choice types etc.
- Auto-generated job scripts when working with tables in the Glue data catalog
I could write an entire blog post on any of these, but for now - take my word for it, Glue is cool.
What is a Glue Job?
Over the years, Glue jobs have become more than just “serverless spark”. Let’s break down the different options available when defining your jobs.
Job Type
At the time of writing, Glue jobs come in 2 flavours:
- Spark ETL - comes with a pre-configured spark session, running in a managed yarn cluster. Use this for your usual “big data” workloads. The jobs take some time to spin up the environment when they start.
- Python Shell - a pure Python shell, pre-loaded with some of the Conda suite libraries, such as Pandas, Numpy, Scipy and Sklearn. Starts up almost instantly. This can also be used as a substitute for AWS Lambda for long-running tasks.
Other than the environment and startup time, there are also some pricing differences. See AWS Glue Pricing for more details.
Language
Python Shell jobs are written in Python (duh!). But Spark ETL jobs can be written in either Scala or Python. The code examples in this post are written in Python for consistency, but choose whichever you like best! Keep in mind the implications on performance that come when choosing PySpark vs Spark in Scala, its native environment, and how you package dependencies.
DPUs - Scaling made simple
A DPU (Data Processing Unit) is how Glue defines the processing power of your job in this crazy serverless world. Each DPU is a container with 4 virtual CPUs, 16GB of RAM and 64GB of disk space.
For Python Shell jobs, your scaling options are limited. You can choose either 0.0625 DPUs (i.e. 1/16 of a DPU == 1GB RAM) or 1 DPU.
However - in the Spark world, you have a few more options. The simplest way to scale your job horizontally - increase the size of your cluster by bumping the number of DPUs.
Another option is to scale vertically - increase the “size” of each machine in your cluster by changing the worker type from Standard (1 DPU == 2 Spark Executors) to either G.1X (1 DPU == 1 Spark Executor) or G.2X (2 DPUs == 1 Spark Executor).
Writing your first Glue Job
Warm up - a simple Python Shell script
Let’s start simple. Imagine you have some JSON-lines files containing the data on some people in S3:
{"name": "Alice", "age": 37, "country": "Montenegro"}
{"name": "Bob", "age": 20, "country": "Canada"}
{"name": "Charlie", "age": 3, "country": "Atlantis"}
…and your friend Chad asked you to convert them to one CSV file, ‘cause that’s the kind of person Chad is. In that case, writing a Glue job to do this is as simple as running a script locally:
import boto3
import pandas as pd
# List .json objects under s3://peoples-data-bucket/json/
BUCKET_NAME = 'peoples-data-bucket'
bucket = boto3.resource('s3').Bucket(BUCKET_NAME)
input_keys = (obj.key for obj in bucket.objects.filter(Prefix='json/')
if obj.key.endswith('.json'))
# Read each .json file into its own dataframe
df_parts = [pd.read_json(f's3://{BUCKET_NAME}/{key}') for key in input_keys]
# Merge data frames
df = pd.concat(df_parts, ignore_index=True)
# Write output as CSV
df.to_csv(f's3://{BUCKET_NAME}/csv/output.csv')
Unlike if we were running this locally, we do not need to fetch any credentials. By default, boto3 uses the default credentials provider, which in the case of your Glue job, will use the job’s role.
Now, let’s create the job:
- Go to the AWS console
- Navigate to AWS Glue -> Jobs -> Add Job
- Enter the job details:
- Job name -
ConvertPeopleDataToCsv - Job role - Create IAM Role -> Create Role:
- Service - Glue
- Permissions -
AWSGlueConsoleFullAccess,AmazonS3FullAccess - Role Name -
GlueJobRole
- Press refresh and choose
GlueJobRole - Type - Python Shell
- This job runs - A new script authored by you
- Job name -
- Next -> Save Job and Edit Script
- Copy-paste the above script into the editor
- Run job -> Save now and run job
Conclusion
Congratulations!🎉 You have just written and successfully run your first Glue job! Other than providing some libraries and a serverless environment to run the script in, this job is no different from what you can run locally. So what’s the point, really?
Well, in isolation, a Glue job is nothing special. However - once we start adding Spark, job arguments, triggers and workflows, we will see how much manual effort can be reduced after we have taken a little time to set everything up.
The above was just a taster. An AWS best practice is to define all your infrastructure (e.g. jobs, roles, buckets) using an Infrastructure as Code solution, to make your infrastructure easier to set up, change, maintain and deploy multiple instances of your infrastructure (e.g. for different regions, or stages (beta/prod)).
Next time, we will do exactly that! We will dive a little deeper and:
- Build, package and deploy a reliable, production-ready job with AWS CDK (Cloud Development Kit)
- Cover some considerations to make when writing Glue jobs, potential pains and how to avoid them.
See you then! :)